Tan Sheng Rong.
Data Science: Cryptocurrency Forecast

Getting Started
-
Data on Cryptocurrency Historical Prices from https://www.kaggle.com/jessevent/all-crypto-currencies/ is downloaded for parsing. The goal is to create an R Shiny dashboard to analyze the top 10 cryptocurrencies, and forecast their price.
-
There are some useless data in the dataset. We first extract the four columns “symbol”, “date”, “open”, “close” from the dataset and work with at one year of latest data (as available in the dataset). The R Shiny application will have a dropdown menu to let the user choose one of the following cryptocurrencies – Bitcoin, Ethereum, XRP, Bitcoin Cash, Litecoin – the top 5 according to https://coinmarketcap.com/. For each such choice, the R Shiny dashboard will predict the price of the cryptocurrency for a user selected number of months in the future, using the best ETS model. The cross-validated accuracy of the best ETS model that is used and the parameters of the best ETS model will be displayed as justification. The forecast will also contain the confidence intervals.
Extras
-
Website Scrapping: The top 5 cryptocurrencies might not always be Bitcoin, Ethereum, XRP, Bitcoin Cash, Litecoin. Thus, the dropdown menu is dynamically generated by scrapping the data on https://coinmarketcap.com/ using the package rvest. Additionally, the actual prices are also scrapped for the forecasted period to compare the accuracy.
-
The initial start and end date range in the Interactive Graph changes dynamically for every cryptocurrency as they each have unique min and max date in the dataset provided.
-
Smoothing methods, Simple forecasting methods are explored.
A live working demo can be found here
Screenshots
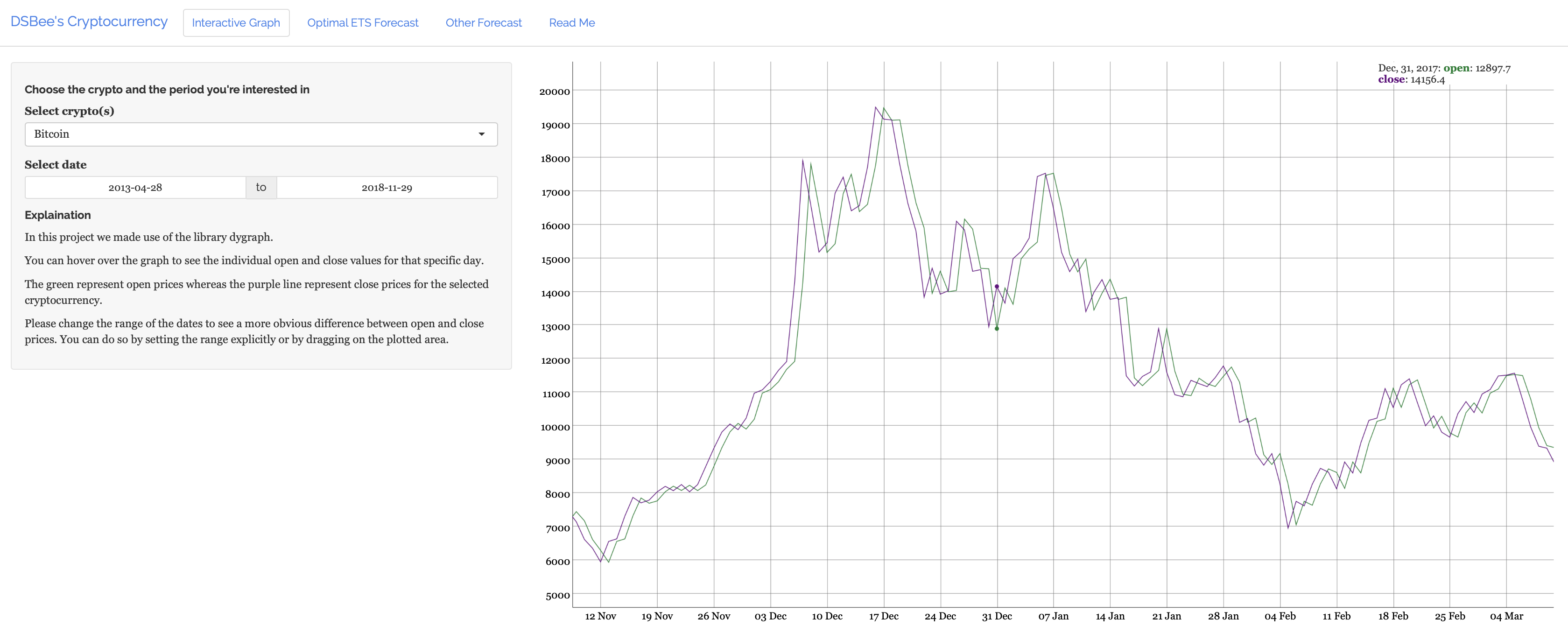
Shows the difference between the opening and closing prices of a selected cryptocurrency.
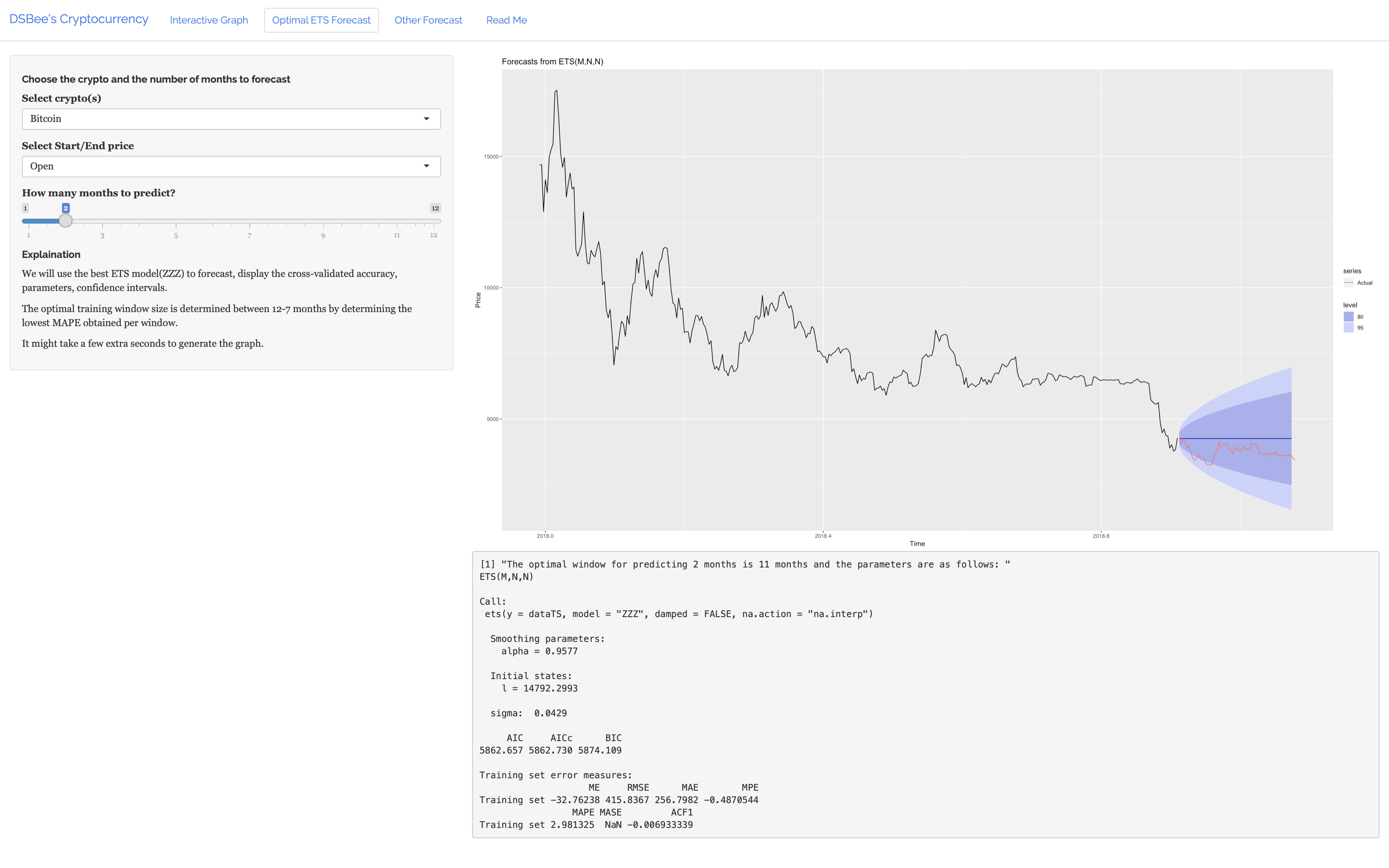
Main forecasting page. Determines the most accurate model and uses it. The model’s accuracy is also displayed. The user has the options of choosing: type of cryptocurrency, open/close price/ number of months to predict. The actual prices are plotted in red.
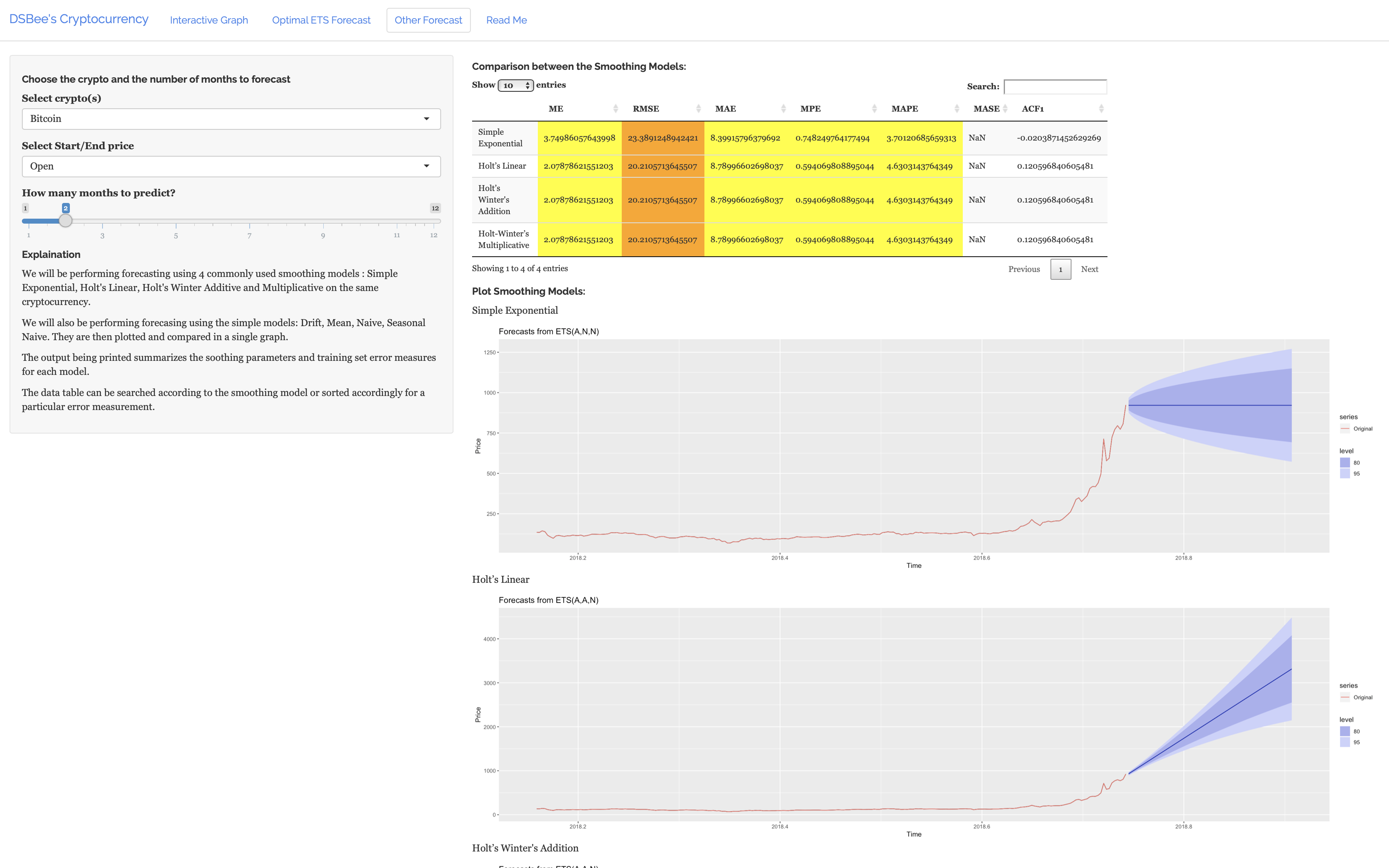
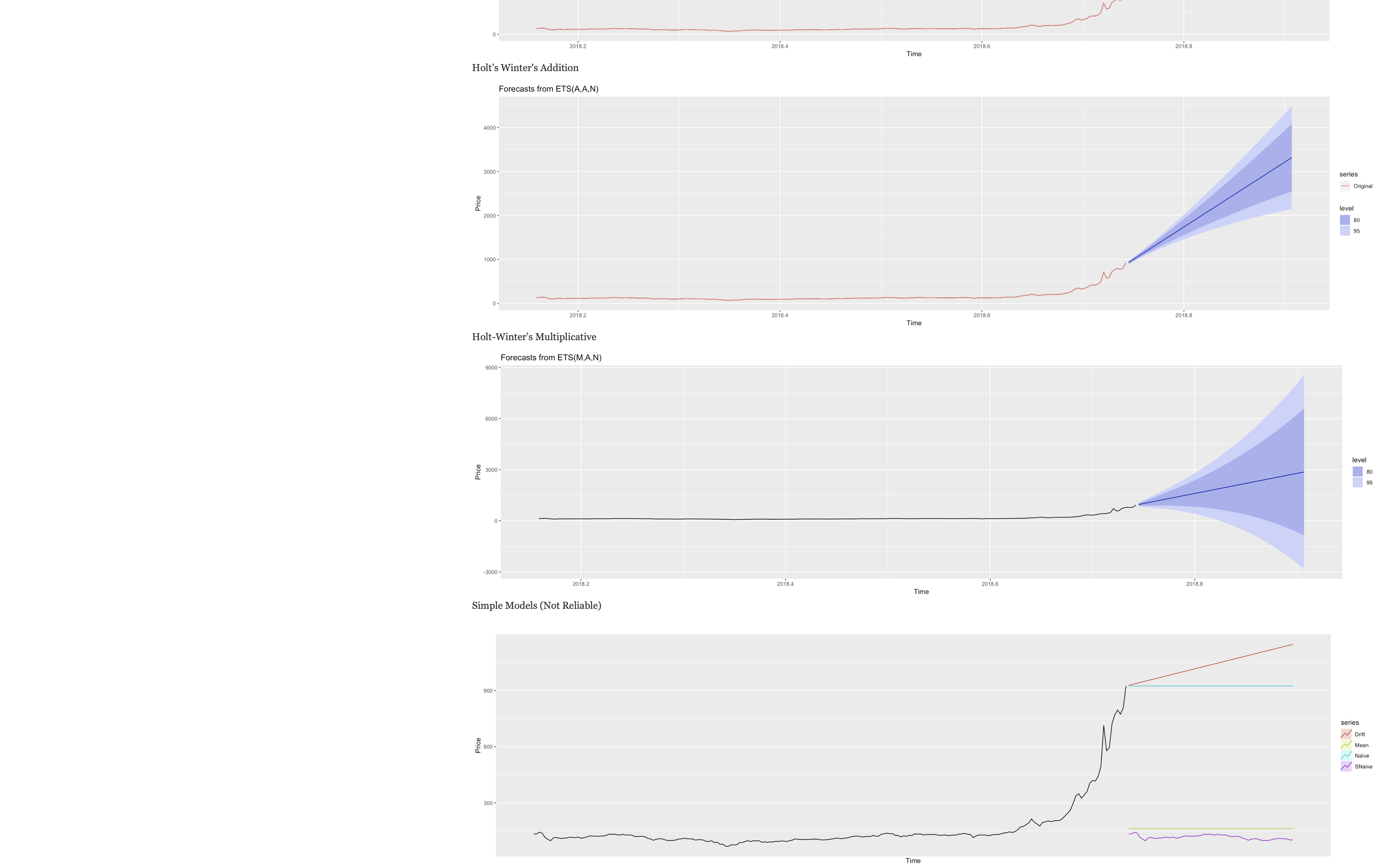
Written on May 2nd , 2019 by Tan Sheng RongExplore other models on the dataset despite them being not as accurate.